
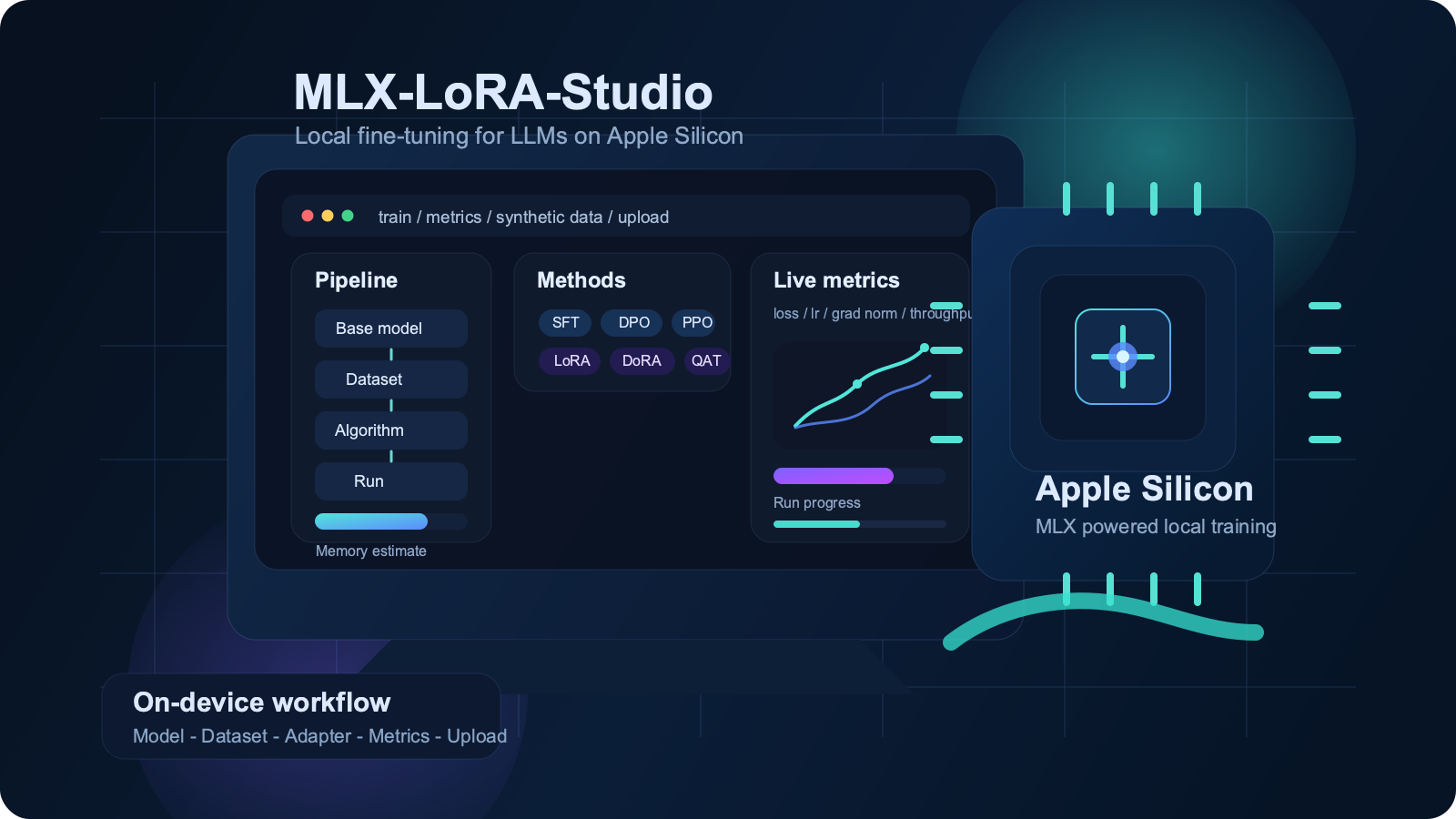
MLX-LoRA-Studio, c’est quoi ?
MLX-LoRA-Studio est une application native macOS destinee au fine-tuning local de LLM sur machines Apple Silicon. Le projet combine une interface SwiftUI/AppKit, un backend Python et l’outillage mlx-lm-lora pour piloter differents types d’entrainement sans passer uniquement par des scripts ou des notebooks.
Le depot cible un cas d’usage assez clair: selectionner un modele compatible MLX, choisir un dataset, lancer un entrainement, suivre les metriques en direct, puis eventuellement publier un adapter vers Hugging Face.
Objectif : faire du fine-tuning local de LLM sur Mac
L’objectif du projet est de proposer un point d’entree graphique pour le fine-tuning local de LLM sur Mac.
Concretement, MLX-LoRA-Studio cherche a couvrir plusieurs besoins:
- lancer des entrainements localement sur Apple Silicon
- rendre visibles les parametres de configuration
- suivre les metriques et les logs pendant un run
- gerer plusieurs executions et reprendre un entrainement
- generer ou preparer des donnees pour certains workflows
- publier des adapters vers Hugging Face
Liens utiles autour de MLX-LoRA-Studio
- Depot principal MLX-LoRA-Studio
- Releases GitHub
- Site du projet
- Projet sous-jacent
mlx-lm-lora - Framework MLX d’Apple
- MLX LM
- Hugging Face
Installation de MLX-LoRA-Studio
Le README de MLX-LoRA-Studio propose deux approches principales: utiliser une release precompilee ou construire l’application depuis les sources.
1. Via les releases GitHub
- ouvrir la page des releases
- telecharger le DMG de la derniere version
- glisser l’application dans
/Applications - enlever la quarantaine macOS avant le premier lancement
Commande indiquee dans le README:
sudo xattr -dr com.apple.quarantine "/Applications/MLX LoRA Studio.app"
Le README precise egalement que cette etape est liee a la distribution hors App Store et au fait que cette premiere release open source n’est pas encore notariee.
2. Construction depuis les sources
Le depot contient un script de build pour compiler et lancer l’application.
git clone https://github.com/Goekdeniz-Guelmez/MLX-LoRA-Studio.git
cd MLX-LoRA-Studio
./script/build_and_run.sh
Autres variantes indiquees:
./script/build_and_run.sh --package
./script/build_and_run.sh --debug
./script/build_and_run.sh --logs
Prerequis
Le projet vise:
- macOS 14 ou plus
- Apple Silicon
- idealement 16 Go de RAM minimum
- davantage de memoire pour les modeles plus gros
Notions et concepts : MLX, LoRA, QLoRA, SFT et DPO
Pour situer l’outil, voici les notions principales qu’il mobilise.
MLX
MLX est le framework machine learning open source d’Apple, pense pour Apple Silicon. MLX-LoRA-Studio repose sur cet ecosysteme pour executer localement les charges d’entrainement et d’adaptation de modeles.
Fine-tuning
Le fine-tuning consiste a reajuster un modele deja entraine sur un nouveau jeu de donnees ou un nouvel objectif. Ici, l’idee est d’adapter un LLM a une tache, un style ou un comportement particulier.
LoRA, DoRA, QLoRA
- LoRA ajoute des couches d’adaptation de faible rang sans re-entrainer tous les poids du modele
- DoRA est une variante autour de cette logique d’adaptation
- QLoRA combine quantification et adapters pour reduire la consommation memoire
Ces approches sont particulierement utiles sur des machines locales avec des ressources limitees par rapport a une infrastructure GPU dediee.
SFT, DPO, PPO et autres methodes
Le projet expose plusieurs modes d’entrainement mentionnes dans le README:
- SFT pour le supervised fine-tuning
- DPO, CPO, ORPO pour les approches basees sur des preferences
- GRPO, Online DPO, XPO, RLHF Reinforce, PPO pour des workflows plus avances
Selon la methode, les donnees attendues et les hyperparametres ne sont pas les memes.
Adapter
Dans ce contexte, un adapter est le resultat d’une adaptation du modele de base. L’application permet de gerer ces sorties, de reprendre un run et de publier l’adapter genere.
Dataset
Le dataset est le jeu de donnees utilise pour l’entrainement. Selon le mode choisi, il peut s’agir:
- d’instructions et reponses pour du SFT
- de paires ou triplets de preferences pour du DPO
- de donnees synthetiques generees localement
Commandes utiles pour MLX-LoRA-Studio
Voici les commandes les plus utiles mentionnees dans la documentation du projet.
Recuperer le code source
git clone https://github.com/Goekdeniz-Guelmez/MLX-LoRA-Studio.git
cd MLX-LoRA-Studio
Construire et lancer l’application
./script/build_and_run.sh
Construire un package
./script/build_and_run.sh --package
Lancer en mode debug
./script/build_and_run.sh --debug
Afficher les logs
./script/build_and_run.sh --logs
Lever la quarantaine macOS sur l’application installee
sudo xattr -dr com.apple.quarantine "/Applications/MLX LoRA Studio.app"
Executer un run YAML avec l’outil sous-jacent
Le README donne aussi un exemple pour reutiliser directement la configuration via mlx-lm-lora:
python -m mlx_lm_lora -c my_run.yaml
Demo : premier workflow de fine-tuning local
Sans entrer dans un retour d’experience, le README decrit une demonstration type qui ressemble a ce flux:
- ouvrir l’application
- aller dans l’onglet
Train - choisir un modele compatible MLX deja present dans le cache Hugging Face
- choisir un dataset
- laisser
SFTpour un premier scenario simple - lancer le run
- suivre les metriques dans
Live Metrics - retrouver le resultat dans
Runs - publier l’adapter vers Hugging Face si besoin
En pratique, la logique de la demo peut se lire en quatre temps.
1. Preparation du run
La premiere etape consiste a selectionner les briques d’entree:
- un modele de base compatible MLX
- un dataset adapte au mode d’entrainement choisi
- un type d’adaptation comme LoRA, DoRA ou QLoRA
- une methode d’entrainement comme SFT ou DPO
L’interface sert ici de point de configuration. Elle expose les champs utiles sans obliger a construire toute la commande manuellement.
2. Lancement de l’entrainement
Une fois la configuration definie, le run peut etre lance depuis l’application. Le README indique que l’outil peut aussi s’occuper de la decouverte ou du provisionnement de l’environnement Python necessaire.
Pendant cette phase, l’objectif est de transformer:
- un modele de base
- une configuration YAML
- un dataset
en un adapter entraine exploitable ensuite.
3. Suivi pendant l’execution
Le README met en avant un ecran Live Metrics qui permet de suivre plusieurs signaux pendant l’entrainement:
- la loss
- le learning rate
- le gradient norm
- le throughput
- les logs Python
L’outil ajoute aussi une estimation memoire et des garde-fous pour limiter les configurations trop lourdes pour la machine locale.
4. Sortie et reutilisation
Une fois le run termine, l’onglet Runs permet de retrouver l’execution et ses artefacts. Le flux de sortie decrit dans la documentation couvre notamment:
- la consultation des runs precedents
- la reprise d’un entrainement
- la recuperation de la configuration associee
- l’upload vers Hugging Face
Autrement dit, la demo ne se limite pas au clic sur Run. Elle montre aussi comment le projet structure l’avant, le pendant et l’apres de l’entrainement local.
L’application decrit aussi d’autres ecrans importants:
Trainpour la configurationLive Metricspour la loss, le debit et les logsSynthetic Datapour la generation de donneesRunspour l’historique des executionsUpload to HFpour la publicationAlgorithm Guidepour les methodes disponibles
Structure du projet et organisation technique
Le README presente une organisation en plusieurs briques:
Sources/pour l’application SwiftBackend/pour les helpers Pythonscript/pour le build et le packagingTests/pour les testsPackage.swiftpour la definition du projet Swift
Cette separation aide a comprendre la logique generale:
- interface native cote macOS
- orchestration des jobs cote Python
- moteur d’entrainement via l’ecosysteme MLX
Points a retenir sur MLX-LoRA-Studio
Quelques elements ressortent de la documentation:
- le projet est limite a macOS et Apple Silicon
- plusieurs methodes d’entrainement sont exposees dans la meme interface
- les metriques, logs et runs font partie du workflow
- l’upload vers Hugging Face est integre
- une partie generation de donnees synthetiques est incluse
Conclusion
MLX-LoRA-Studio est un projet open source oriente vers le fine-tuning local de LLM sur Apple Silicon. Sa documentation presente une interface native pour piloter plusieurs modes d’entrainement, suivre les runs et gerer la publication des adapters.
Pour ceux qui veulent explorer l’ecosysteme MLX, comprendre la place de LoRA et QLoRA sur Mac, ou regarder comment un workflow de fine-tuning local peut etre structure, ce depot fournit une base de lecture utile.