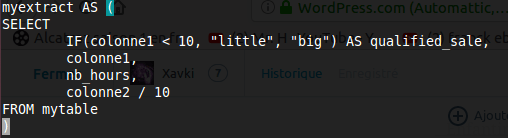
[SQL] : créez des constantes et des noms de résultats
DBA et développeur, cet article est pour vous… y’en faut pour tous les goûts comme on dit. Voici deux outils peu utilisés dans les bases de données que j’ai pu voir récemment. Et pourtant, ils permettent de simplifier votre script…